Meta dùng dữ liệu người dùng Facebook, Instagram để dạy trí tuệ nhân tạo
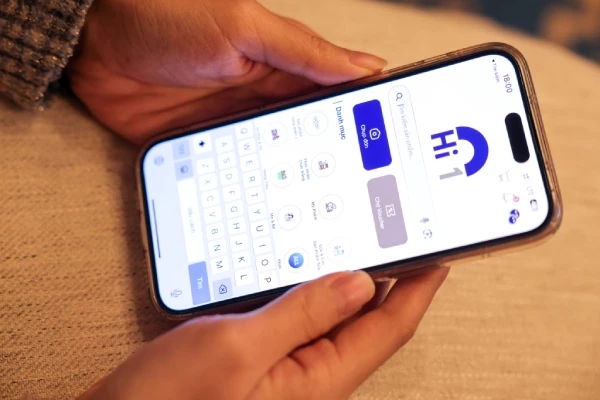
Meta Platforms đã sử dụng các bài đăng công khai trên Facebook và Instagram để đào tạo trợ lý ảo Meta AI mới của mình.
Trong cuộc phỏng vấn với Reuters, Nick Clegg – Chủ tịch Các vấn đề toàn cầu Meta – cho biết công ty sử dụng các bài viết Facebook và Instagram công khai để đào tạo trợ lý ảo AI mới. Tập đoàn không dùng những đoạn chat cá nhân của người dùng và cũng áp dụng các biện pháp để lọc thông tin riêng tư khỏi bộ dữ liệu công khai.
“Chúng tôi đã cố gắng loại trừ các tập dữ liệu có nhiều thông tin cá nhân”, ông Clegg cho biết và nói thêm rằng, “phần lớn” dữ liệu được Meta sử dụng để đào tạo là công khai.
Bài đăng công khai trên Facebook và Instagram đã được Meta sử dụng để đào tạo trợ lý AI mới
Bình luận được ông Clegg đưa ra giữa lúc các hãng công nghệ như Meta, OpenAI, Google đang bị chỉ trích vì sử dụng thông tin lấy từ Internet mà không được sự cho phép để đào tạo các mô hình AI.
Meta AI là sản phẩm quan trọng nhất trong số các công cụ AI hướng tới người tiêu dùng đầu tiên của Meta. Sự kiện năm nay của công ty công nghệ Mỹ chủ yếu thảo luận về trí tuệ nhân tạo, không giống như các hội nghị trước đây tập trung vào thực tế ảo và tăng cường.
Công ty cho biết, Meta đã tạo ra trợ lý này bằng cách sử dụng một mô hình tùy chỉnh dựa trên mô hình ngôn ngữ lớn Llama 2 mạnh mẽ mà công ty đã phát hành vào tháng 7. Nó sẽ có thể tạo ra văn bản, âm thanh và hình ảnh, đồng thời sẽ có quyền truy cập vào thông tin thời gian thực thông qua quan hệ đối tác với công cụ tìm kiếm Bing của Microsoft.
Theo lãnh đạo Meta, công ty còn áp đặt hạn chế an toàn đối với nội dung mà công cụ có thể tạo ra, chẳng hạn cấm tạo ảnh giống với các nhân vật của công chúng.
Khi được hỏi Meta có áp dụng biện pháp nào để tránh tái tạo lại hình ảnh bản quyền hay không, người phát ngôn công ty nhắc đến các điều khoản dịch vụ mới, cấm người dùng tạo ra nội dung vi phạm quyền riêng tư và quyền sở hữu trí tuệ.


.jpg)